

Basic DNA Sequencer Specifications
There are a few general specifications that should be well know for a DNA sequencing platform. They’re kind of the high level specs that to a first approximation you can use to figure out the performance of a platform in general terms.
The Metrics
Of course, if you’re considering a platform it always makes sense to benchmark it for your particular application. The general specs I would expect to know are:
The per-base accuracy on the total delivered dataset (overall error rate).
Ideally you’d have errors broken down by insertion/deletion/mismatch too.
The average read length.
The number of bases delivered in a run (at the above per-base accuracy).
Run and instrument cost.
I’d personally want to have a reasonable handle on these these numbers before purchasing a DNA sequencer. It’s reasonable for these numbers to be specified for a particular sample type (like human genomic DNA). And for a particular sample prep protocol (PCR-free etc.).
Other metrics are of course useful and welcome. In particular one Discord user pointed out that yield plots such as the one shown below are important and more valuable than the over all per-base accuracy:
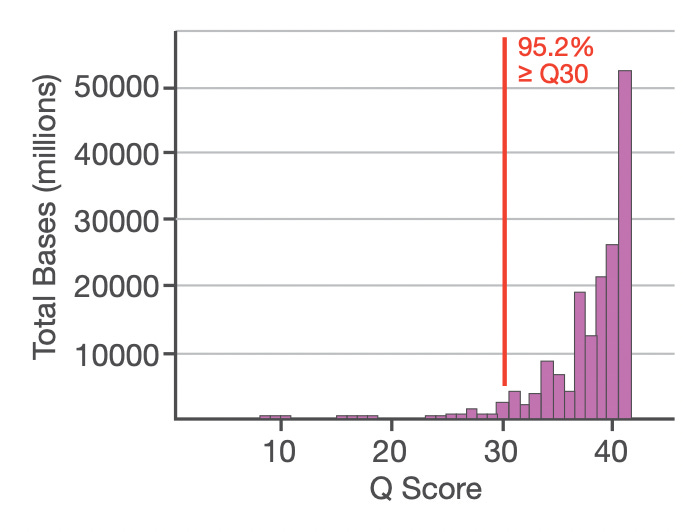
And I would agree if these are for emQ (Q-scores calibrated by alignment) or the Q-scores are known to be well calibrated these can be very useful and provide more detailed information about a platforms performance and utility.
So the above metrics are personally the ones I’d want to have a rough handle on. It doesn’t necessarily matter if they’re “bad” just means you might have to think a bit more carefully about how this platform would work for your application.
Refunding runs
In addition to this it’s great to have some acceptance/fail criteria for runs. I.e. if data quality is below X it’s a run failure and the consumables will be replaced/refunded. Hopefully this rarely happens. Hopefully it rarely happens in part because assigning blame can be complicated (maybe you screwed up the prep) and quality metrics for non-standard data types can be difficult to agree on.
Summary
I have a pretty good understanding of these metrics for most platforms (except Oxford Nanopore’s). Part of this is possibly because flow cells and chemistries on ONTs platform change pretty regularly. Partly it’s because statements from the company are not very clear (modal per-read accuracy doesn’t really map to the specification above and is difficult to reason about).
While I’m personally not really in the market for an ONT sequencer, it will be interesting to continue to try and figure out these numbers!